探索 Stable Diffusion WebUI 模型分類:推薦的各領域 Checkpoint與LoRA

目錄
如果還沒有安裝AUTOMATIC1111 stable-diffusion-webui的話可以參考:
Stable diffusion
簡單來說就是一個文字生成圖像的模型,diffusion 為擴散模型,而我們再算圖會比較常使用到,LoRA、Checkpoint、Base Model。
- LoRA: 一種輕量化的模型微調技術,用於添加特定風格或主題調整。
- Checkpoint: Stable Diffusion 的核心模型檔案,決定生成影像的風格與效果。
- Base Model: 未經微調的原始模型,適合作為創作的通用基礎。
Base models
Stable Diffusion 模型的「核心」,能夠理解文本輸入(如 Prompt)並生成圖像。 是一個經過大規模數據集訓練的原始模型,具有最基礎的圖像生成能力。但是針對單一的主題、應用場景效果可能不會到非常理想。
檔案大小:4-10+GB不等
- Stable diffusion v1.5
- Stable Diffusion XL
- Flux.1 dev
CheckPoint
Checkpoint 是指模型訓練過程中的保存點。是基於Base Model 微調後完整模型文件,微調通常針對特定風格、特定主題或應用場景,進行額外訓練。所以在特定的主題跟場景效果會比一般的Base models好非常多。
檔案大小:2-7+GB
CheckPoint使用方法
要說到哪裡可以下載到最多種類的Checkpoint,非civitai莫屬了。
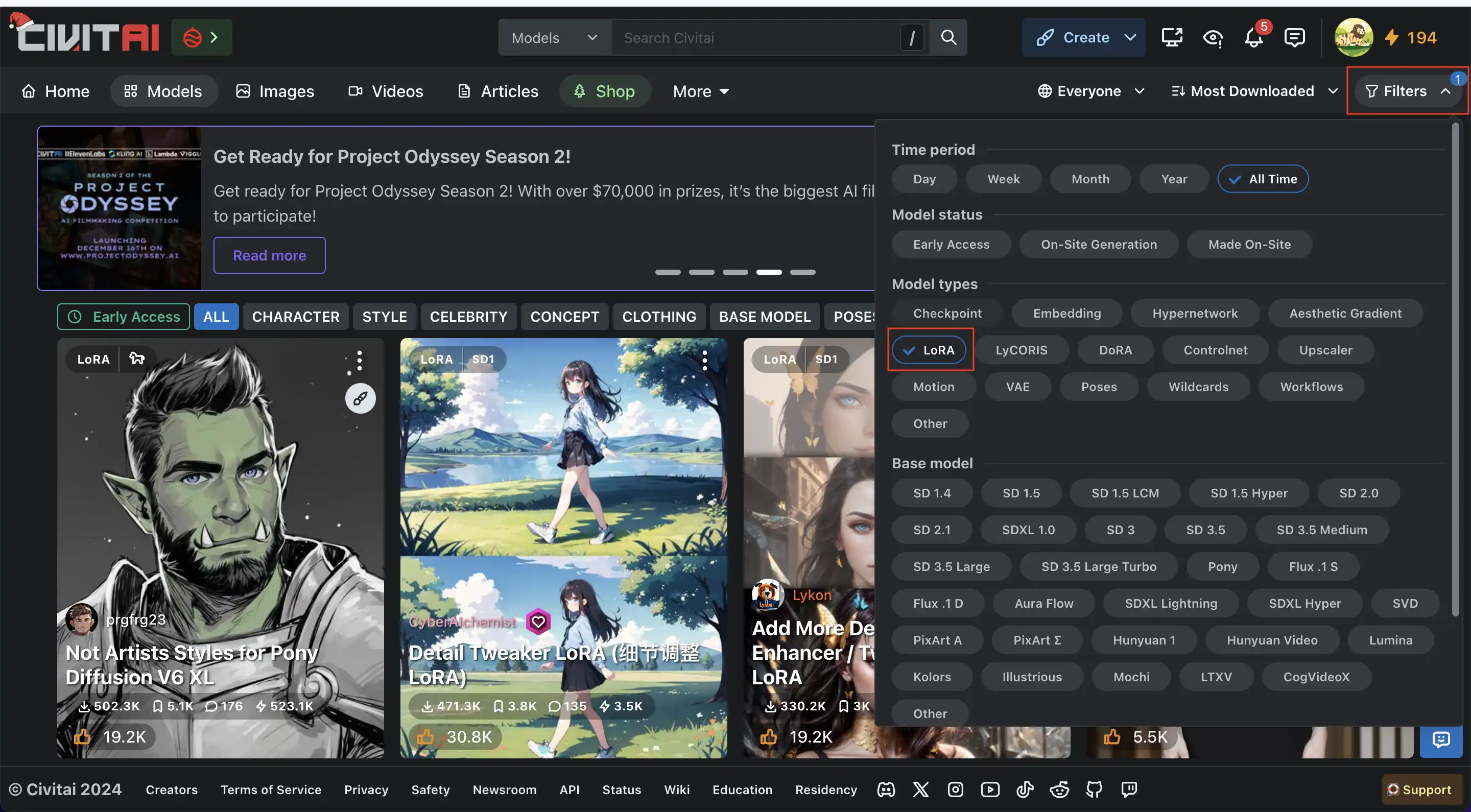
點進去civitai後點選右上角的,“Fliters”,然後在 “Model type” 這裡勾選,“Checkpoint”,就可以在 civitai上搜尋所有的CheckPoint。
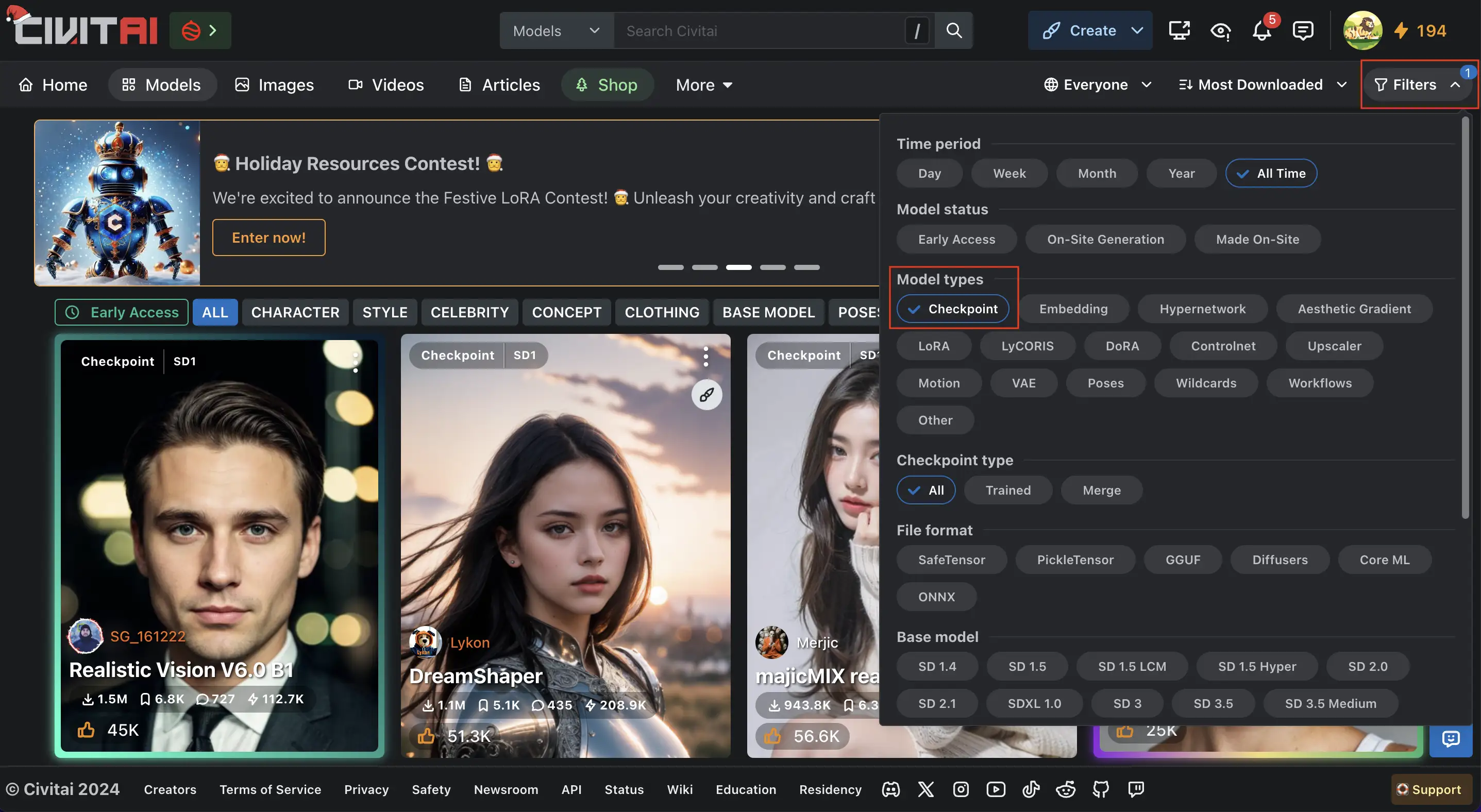
這裡也可以根據不同的主題與應用場景去搜尋,例如:Background(場景) Bulding(建築)、Colthing(服裝)、Style(風格)等等。
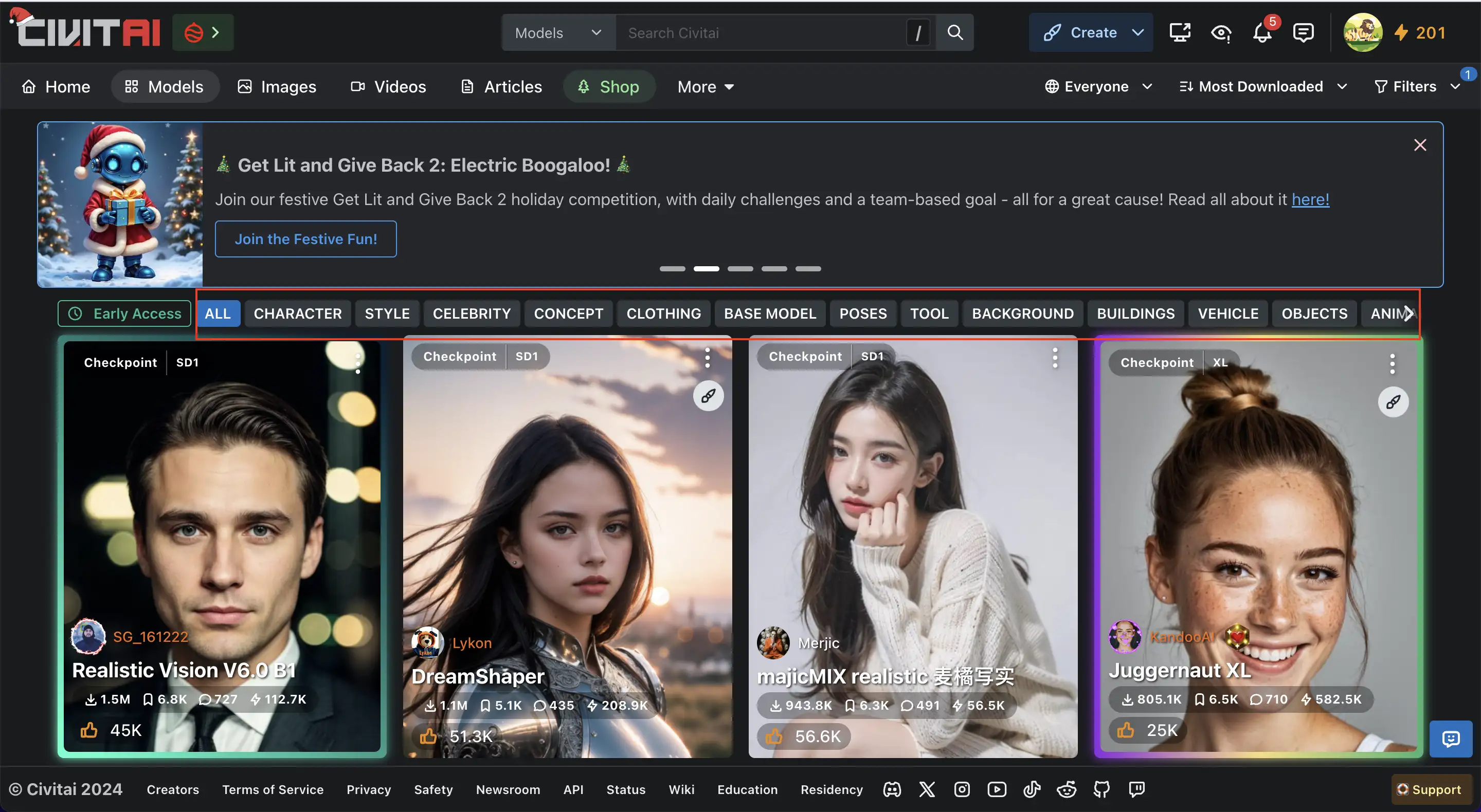
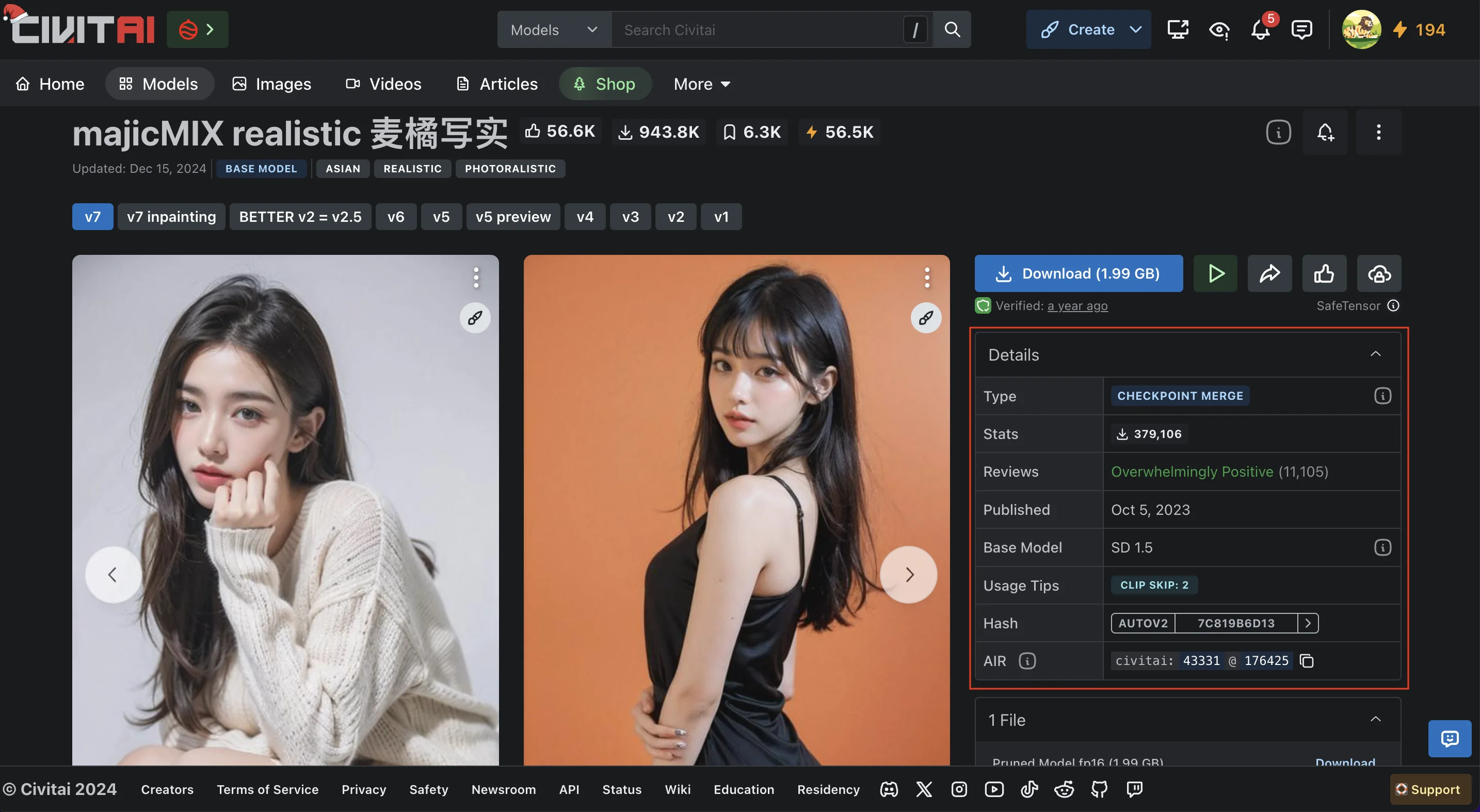
點進去之後這邊可以看到,這個CheckPoint的資訊,類型、Base Model等的等,下載的按鈕也在這裡。
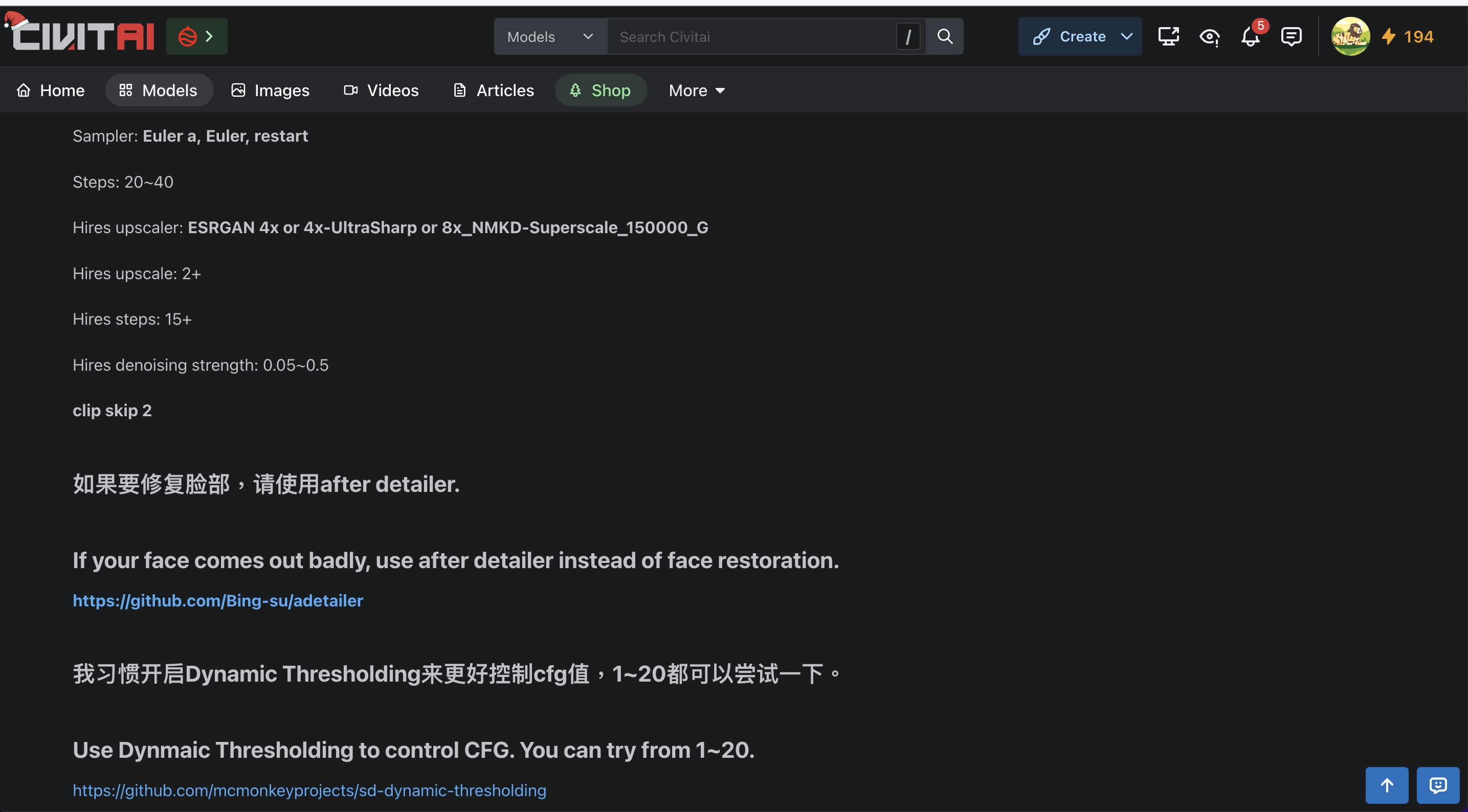
往下滑之後可以看到使用說明,所有的checkpoint使用方法都不太一樣,所以下載之前一定要看清楚,作者通常會在這裡說明用什麼參數、權重、以及需要可以什麼LoRA使用。
按下載之後先cd 到 stable-diffusion-webui 然後將下載好的檔案(.safetensors、.ckpt)丟到
stable-diffusion-webui/models/stable-diffusion 。在stable-diffusion-webui模型旁邊,按下重新整理,再點選那個CheckPoint就可以使用了。
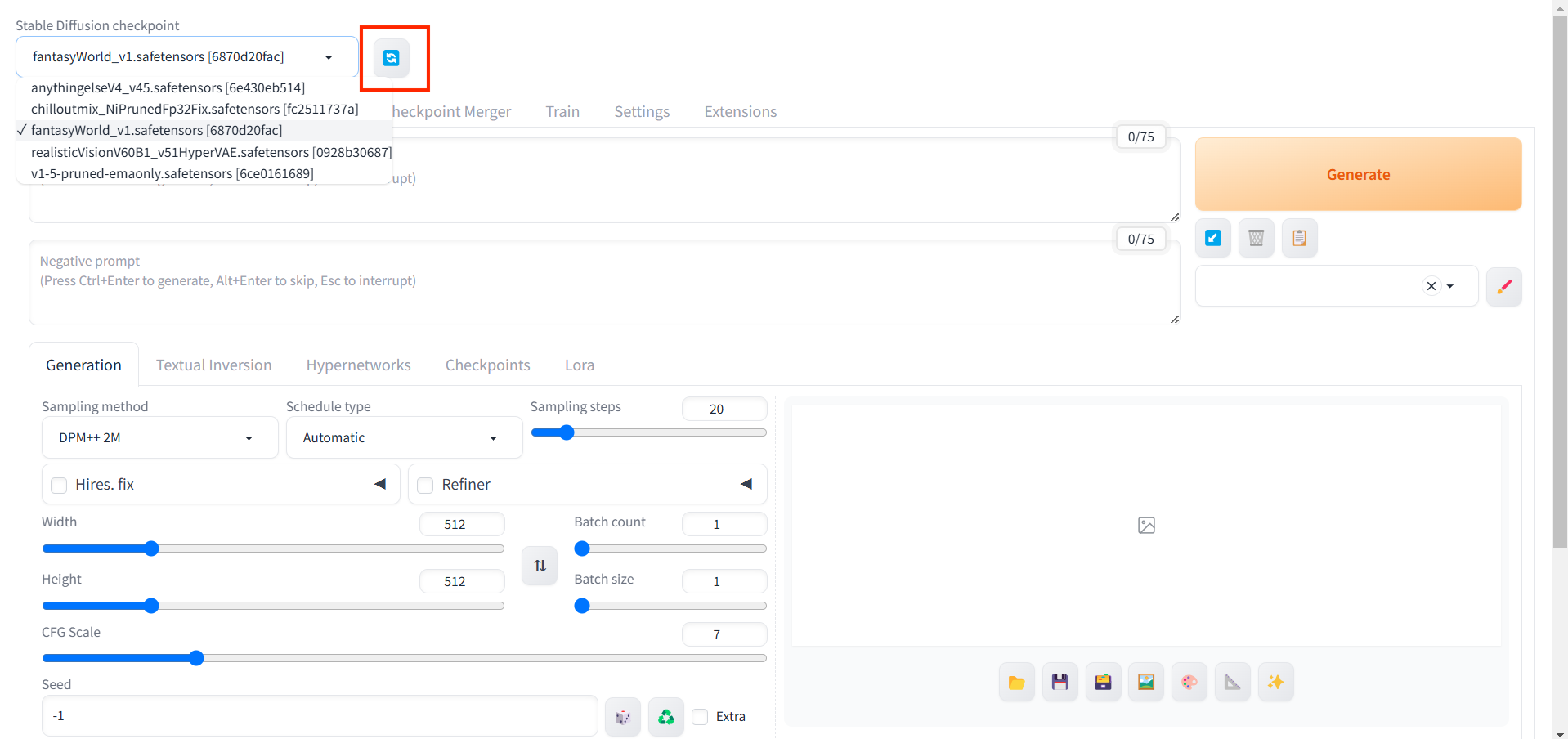
Embedding(Textual inversion)
Embedding 是一種詞嵌入技術,主要針對 文本提示詞(Prompts) 進行調整或優化。簡單來說就是將非常多常用的提示詞變成文字合集。
檔案大小:KB-MB。
比較常用的就是easynegative、bad-hands-5,這兩個都是作為負面提示詞(negative prompt)使用,easynegative是由許多算壞圖片負面提示詞合集,bad-hands-5是針對手指變形的負面提示詞。
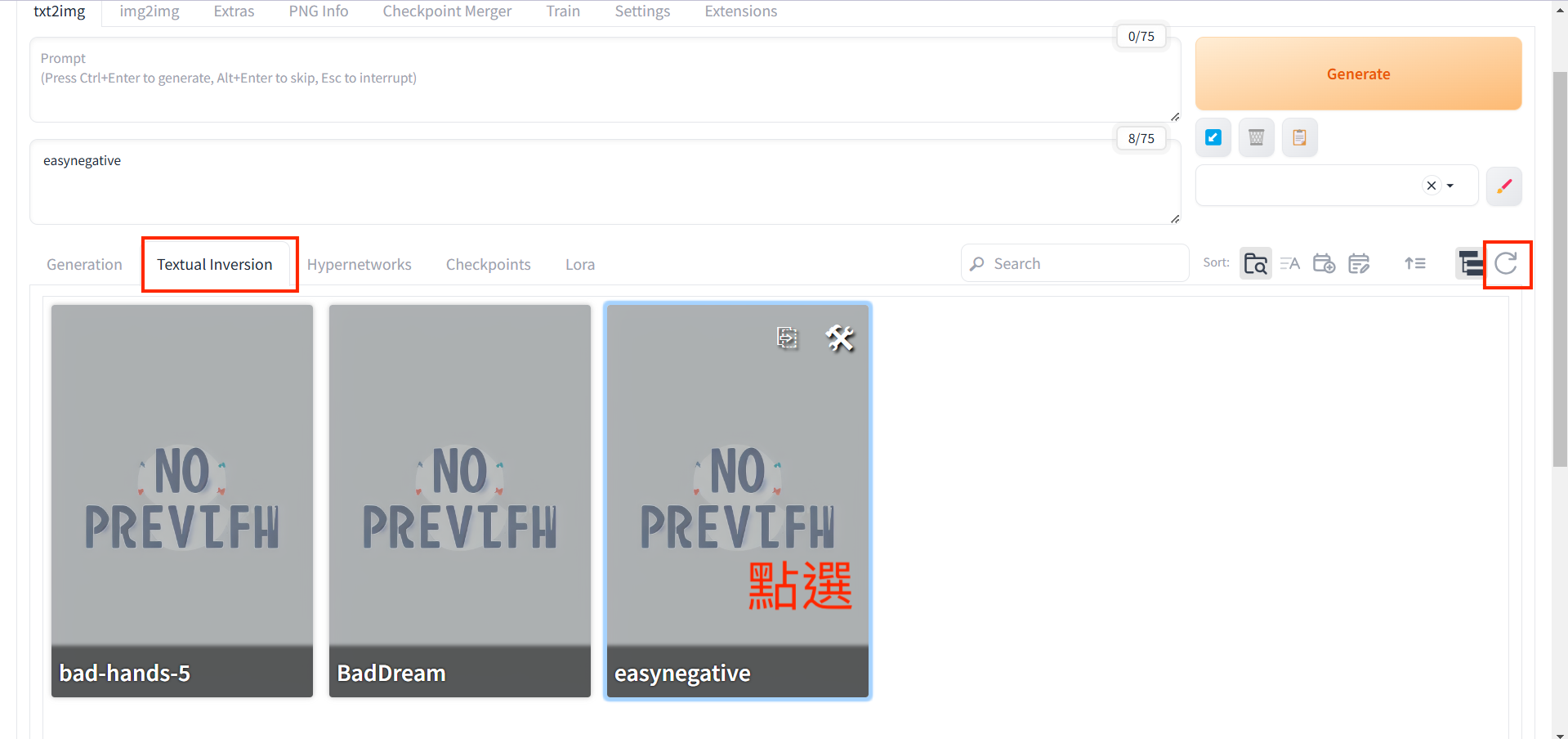
下載下來之後(.pt),要放在stable-diffusion-webui\embeddings,然後打開stable-diffusion-webui,點選 “Textual inversion”,再點選旁邊的 “refresh箭頭”,就可以看到自己剛剛丟進去的embedding了。然後再輸入Negative prompt得時候點一下embedding,就會帶入到Negative prompt裡面了。
LoRA
LoRA 是一種輕量化的模型微調方法。它不會改變 Base Model 本身的權重,而是透過額外的權重變換來調整模型行為,因此檔案會比較小大概落在幾百MB。不過這邊要注意的是,LoRA無法單獨使用,需要搭配CheckPoint。
檔案大小:幾百MB
LoRA 使用方法
這邊一樣要前往
點進去civitai後點選右上角的,“Fliters”,然後在 “Model type” 這裡勾選,“LoRA”,就可以在 civitai上搜尋所有的LoRA。
挑選一個自己喜歡的點進去。由於每個LoRA都有可能有要搭配使用的CheckPoint,還有權重值要給多少,所以在下載之前要看清楚底下的使用説明。
將下載好的檔案,放在 stable-diffusion-webui/models/LoRA路經當中後,打開stable-diffusion-webui。先點選 ":Lora",再點選旁邊的 “refresh箭頭”,就可以看到自己剛剛丟進去的Lora了。
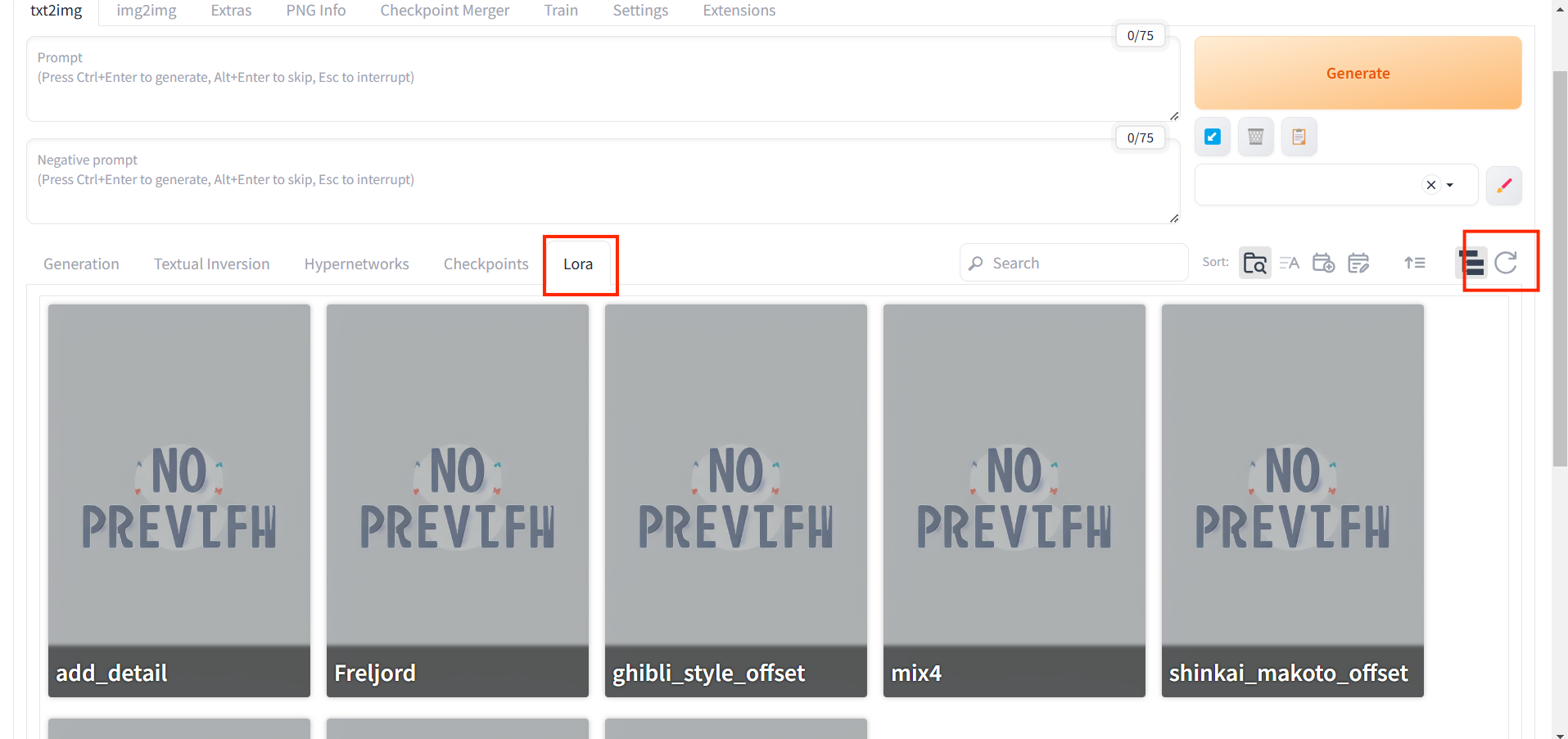
使用方法也非常簡單,在我們要輸入prompt生成圖像時prompt欄位,加入 lora:name:weight
- name指得就是模型名稱
- weight指得就是權重值 0-1
Example:
<lora:chilloutmixss_xss10:0.7>
意思就是使用chilloutmixss_xss10這個LoRA,權重直0.7的意思
也可以直接在prompt的時候直接點Lora,stable-diffusion-webui會自己把Lora的名稱帶進去prompt裏面,跟Embedding的使用方法一樣。
Stable Diffusion Model 推薦
其實直接用base models去算圖結果可能並不會到非常理想,因為base models本身的涵蓋範圍很廣,他可以產出風景、建築、藝術、插畫等等,因此他在單一領域的表現可能不會比建立在他基礎底下建立的models還要好。
有些模型就是專注於產出美女、人像、甚至是可以產出韓國偶像的model,因此如果有明確要產出的圖像目標,就可以去找那個領域的models來使用效果會更好。
雖然Stable diffusion v1.5的下一代 Stable Diffusion XL非常厲害,但是基於Stable diffusion v1.5 訓練出來的CheckPoint在特定領域下,也可以生成不下於Stable Diffusion XL的影像品質哦。這邊我會推薦幾個我有使用過的CheckPointt。
ChilloutMix (亞洲臉孔美女)
模型類型:CheckPoint
下載地址:chilloutmix
CheckPoint專門來生成高擬真人物的models,尤其是亞洲臉孔的美女,真的是蠻不錯的,prompt給的簡短的 beauty asian girl,都可以跑出非常不錯的人物。

▲ 這裡的圖是直接使用,ChilloutMix去生成圖象,並沒有包含LoRA,只有使用easynegative、bad-hands-5這兩個embeddings而已。算出來的結果會非常乾淨細節也不錯。

▲ 不過如果覺得覺得膩了,ChilloutMix也可以搭配LoRA使用,這裡的圖我是搭配Cute_girl_mix4這個LoRA使用。會感受到臉型不太一樣,會更加可愛一點。

▲ 這裡我是使用了ChilloutMixss,這個LoRA,出來的妝感會比較重一點。但是這個LoRA的權重不要給太重,大概落在0.4~0.7就好,
<lora:xiaoshazi:0.4>,如果給太重會影響到面容。
Realistic Vision (真人風格)
模型說明:Realistic Vision 是Stable Diffusion 1.5 訓練的模型,能夠產生高度擬真風格、高細節的圖片,非常擅長動物與人像。
模型類型:CheckPoint
下载地址::Realistic Vision

▲ 算完真的有被嚇到….這真的是AI嗎!?真的不是傳一張世界某個角落的人像照片給我?

Realistic Vision 可以搭配這個LoRA使用
主要是增加圖片的細節以及降低對比,參數可能要多條幾次才會出來比較理想得圖片,我是給大約-1~1。
<lora:add detail:-1>
但是Realistic Vision 再生成純背景的時候,例如自然景觀的時候就比較不適合了。
AnythingElse V4 (二次元)
模型說明:是專門針對動漫風格的圖像生成進行訓練的模型,可以產出非常高細節、高質量的動漫風格圖像。
模型類型:CheckPoint
下載地址:AnythingElse V4


吉卜力
宮崎駿迷一定要玩玩看這個LoRA,這邊我有搭配這個LoRA去使用,二次元風格有超級多的LoRA,尤其是知名的動漫。
模型類型:LoRA
下載地址: Studio Ghibli Style LoRA

不過這邊要注意的是,要給得非常具體,才有辦法出來最精準的形象哦。例如:
prompt:
ghibli style, san (mononoke hime), 1girl, armlet, bangs, black hair, black undershirt, breasts, cape, circlet, earrings, facepaint, floating hair, forest, fur cape, green eyes, jewelry, looking at viewer, medium breasts, nature, necklace, outdoors, parted bangs, shirt, short hair, sleeveless, sleeveless shirt, solo, tooth necklace, tree, upper body, white shirt , ((masterpiece))
最好是把外觀描述得越詳細越好,然後前面還要提到動漫名稱以及角色名稱。san (mononoke hime)
Fantasy World
模型說明: 二次元遊戲場景。
模型類型:CheckPoint
下載地址: Fantasy World




(持續更新)
結論
以上就是幾個我玩過效果比較好的CheckPoint、和LoRA。這篇文章會持續更新,因為模型跟LoRA進步的速度很快,可能每幾週又有新的CheckPoint可以玩了。
Stable Diffusion:
Recent Posts
目錄